مبحث مورد بحث در این مقاله فشرده سازی اطلاعات در Sql Server می باشد .
یکی از مهم ترین چالش های اکثر مدیران پایگاه داده رشد زیاد داده ها و حجم کل دیتابیس می باشد که به تبع آن این موضوع باعث کند شدن اجرای کوئری های ارسال شده توسط برنامه نویسان بر روی جداول می شود . به همین دلیل می بایست با روش هایی جهت افزایش حجم بسیار بالای دیتا جلوگیری کرد .
فشرده سازی اطلاعات در SQL SERVER
با استفاده از عملیات فشرده سازی اطلاعات یا Data Compression می توان دیتای پایگاه داده ها را به صورت فشرده با حجم کمتر نگهداری کرد.
عملیات فشرده سازی بر روی موارد موجود در زیر قابل اعمال شده می باشد :
- جدول هایی که به صورت HEAP می باشند .
- ایندکس هایی که Clustered می باشند .
- آیندکس هایی که NonClustered می باشند .
- بر روی Index View ها
زمانی که از سمت Application دیتای خاصی درخواست می شود ، داده های فشرده شده مورد نظر به حافظع Cache انتقال داده می شود ، بعد از این فرآیند CPU کار Uncompressed کردن دیتا را انجام می دهد ، البته این فرآیند برای Cpu هزینه زیادی ندارد .
فشرده سازی اطلاعات در SQL Server به منظور کاهش فضایی که توسط دادههای ذخیره شده در پایگاه داده استفاده میشود، انجام میشود. این کار میتواند به بهبود عملکرد کوئری و کاهش زمان انجام عملیات بر روی دادههای ذخیره شده در پایگاه داده منجر شود. در SQL Server، فشرده سازی اطلاعات به صورت دو صورت انجام میشود:
1- فشرده سازی سطری: در این روش، دادهها در سطرهای جدول فشرده میشوند. این کار معمولاً با کاهش تعداد صفحات مورد استفاده برای ذخیره دادهها، منجر به بهبود عملکرد کوئری و کاهش زمان اجرای آنها میشود.
2- فشرده سازی ستونی: در این روش، دادههای یک ستون در یک بخش از حافظه ذخیره میشوند. این کار معمولاً با کاهش تعداد صفحات مورد استفاده برای ذخیره دادهها، منجر به کاهش مصرف فضا و افزایش سرعت اجرای کوئریها میشود.
برای فشرده سازی اطلاعات در SQL Server، میتوان از روشهای مختلفی مانند فشرده سازی سطری، فشرده سازی ستونی، فشرده سازی صفحهای و فشرده سازی مضاعف استفاده کرد. برای استفاده از این امکانات، باید تنظیمات مربوط به فشرده سازی در SQL Server تنظیم شود.
فشرده سازی اطلاعات در SqlServer به دو روش زیر انجام می شود :
-
فشرده سازی در سطح ردیف و یا (Row Data Compression)
-
فشرده سازی در سطح صفحات و یا (Page Data Compression)
1 – فشرده سازی در سطح رکورد (Row Data Compression)
این مدل فشرده سازی در دو مرحله زیر انجام می شود :
- حجم Meta Data هر رکورد در ابتدا به حداقل می رسد(منظور از متا دیتا اطلاعاتی مانند آفست ، طول و اطلاعات سطر و ستون ها می باشد) .
- در ادامه فیلد ها و داده های با طول ثابت به داده های با طول متغییر تبدیل می شود . مثل : VarChar
<<اسکریپت های موجود در این مقاله در انتهای صفحه موجود است .>>
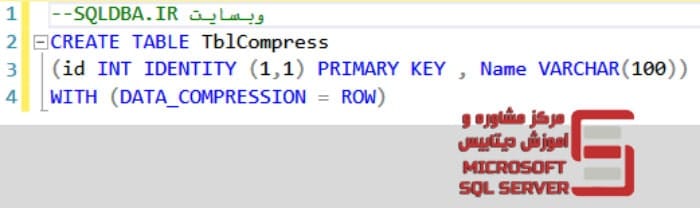
در اسکریپت بالا مشاهده می شود که جدولی با نام TblCompress ایجاد کردیم که اطلاعات را به صورت فشرده در سطح رکورد دارد.
و در اسکریپت زیر جدولی که از قبل موجود بوده را به جدولی با خاصیت فشرده سازی تبدیل میکنیم :

2 – فشرده سازی در سطح صفحات و یا (Page Data Compression)
دومین روش فشرده سازی اطلاعات در سطح پیج (Page) بوده که این روش قوی تر و بهینه تر از روش فشرده سازی ردیف می باشد .
در این مدل اطلاعات مشترک در سطر یک صفحه مشترکا مورد استفاده قرار میگیرد ، تکنولوژی موجود در این روش در زیر آمده است :
- روش قبلی (Row Compression) که در بالاتر گفته شد نیز در این روش بکار برده شده است .
- PreFix Compression : در هر صفحه به ازای هر ستون موجود PreFix های تکراری یافت شده و در Header مختص فشرده سازی ذخیره می شود . (موقعیت این هدر بعد از هدر اصلی Page می باشد) و در هر قسمتی که به این PreFix اشاره شده باشد عدد مختص جهت شناسایی شدن آن ها نسبت داده می شود .
- Dictionary Compression : در این روش مقدار های تکراری موجود در یک Page پیدا شده و در Header مختص فشرده سازی ذخیره می شود . در روش قبلی فقط در یک ستون جستجو می شود ولی در این روش در کل Page اعمال می شود .
در ادامه جدولی جدید برای فعال سازی این روش می سازیم:
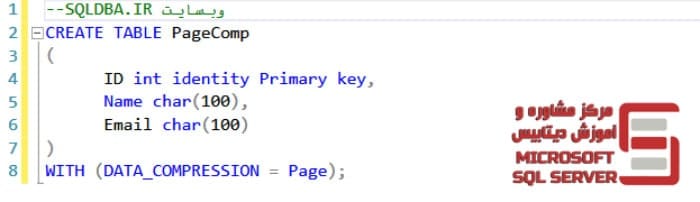
و برای تغییر خاصیت جداول موجود برای فشرده سازی از اسکریپت زیر استفاده میکنیم :

باید به این نکه نیز توجه کرد که در این روش فقط دیتای جداول و ایندکس های کلاستر فشرده خواهد شد و این فرآیند بر روی ایندکس های NonClustered تاثیری نخواهد داشت .

جهت فشرده سازی همه ی ایندکس های یک جدول خاص از اسکریپت زیر استفاده کنید :

نکته مهمی که در بحث فشرده سازی اطلاعات وجود دارد این است که ما قبل از فشرده سازی اطلاعات می بایست دیتای خود را بررسی کرده و بعد از اطمینان از حصول نتیجه رضایت بخش فرآیند فشرده سازی را انجام دهیم ، به طور مثال فشرده سازی بر روی دیتای متنی با درصد خیلی بالاتری انجام می شود و همچنین این نکته رو باید در نظر داشت که این فرآیند بر روی ایندکس ها و جداول تراکنشی با Read و Write بالا مناسب نمی باشد .
برای بررسی میزان فشرده سازی اطلاعات قبل از انجام میتوان از رویه های ذخیره شده زیر نیز استفاده کرد تا بدون فشرده سازی واقعی از مقدار فشرده سازی قابل انجام مطلع شد .
با دو پراسیجر زیر می توان این میزان را بررسی کرد .

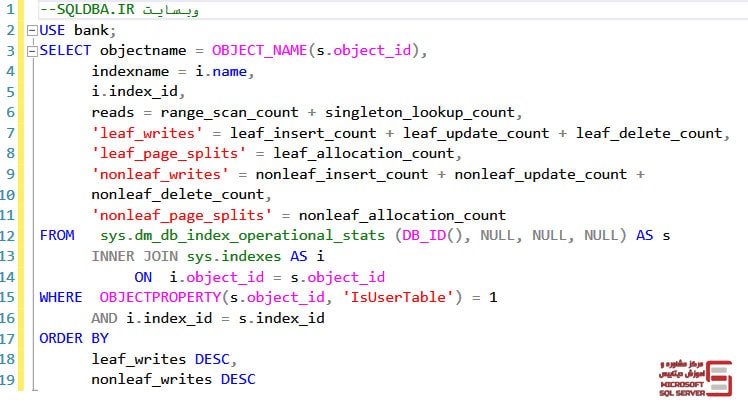
برای بررسی میزان Read و write ایندکس ها از اسکریپت زیر استفاده کنید :
در لینک زیر می توانید مقاله متناظر این مطلب در وب سایت مایکروسافت را مشاهده کنید .
اسکریپت های موجود در مطالب را میتوانید از باکس زیر کپی کنید .
--SQLDBA.IR وبسایت
CREATE TABLE TblCompress
(id INT IDENTITY (1,1) PRIMARY KEY , Name VARCHAR(100))
WITH (DATA_COMPRESSION = ROW)
------------------------------------------------------------------------------------------------
Alter TABLE PageComp REBUILD WITH
(DATA_COMPRESSION=Row );
------------------------------------------------------------------------------------------------
Alter TABLE PageComp REBUILD WITH
(DATA_COMPRESSION=PAGE );
-----------------------------------------------------------------------------------------------ت
ALTER INDEX Index_name ON DataBase_name.Table_name
REBUILD WITH(DATA_COMPRESSION=PAGE)
------------------------------------------------------------------------------------------------
ALTER INDEX ALL ON Sales.SalesOrderHeader
REBUILD WITH(DATA_COMPRESSION=PAGE)
------------------------------------------------------------------------------------------------
--SQLDBA.IR وبسایت
ALTER INDEX ALL ON dbo.TestCompress
REBUILD WITH(DATA_COMPRESSION=PAGE)
------------------------------------------------------------------------------------------------
-- نمایش میزان فضای برگشتی بعد از عملیات فشرده سازی صفحات
EXEC sp_estimate_data_compression_savings 'schemaname', 'TableName', NULL, NULL, 'PAGE';
-- نمایش میزان فضای برگشتی بعد از عملیات فشرده سازی سطرها
EXEC sp_estimate_data_compression_savings 'schemaname', 'TableName', NULL, NULL, 'ROW';
------------------------------------------------------------------------------------------------
USE bank;
SELECT objectname = OBJECT_NAME(s.object_id),
indexname = i.name,
i.index_id,
reads = range_scan_count + singleton_lookup_count,
'leaf_writes' = leaf_insert_count + leaf_update_count + leaf_delete_count,
'leaf_page_splits' = leaf_allocation_count,
'nonleaf_writes' = nonleaf_insert_count + nonleaf_update_count +
nonleaf_delete_count,
'nonleaf_page_splits' = nonleaf_allocation_count
FROM sys.dm_db_index_operational_stats (DB_ID(), NULL, NULL, NULL) AS s
INNER JOIN sys.indexes AS i
ON i.object_id = s.object_id
WHERE OBJECTPROPERTY(s.object_id, 'IsUserTable') = 1
AND i.index_id = s.index_id
ORDER BY
leaf_writes DESC,
nonleaf_writes DESC

![tempdb در sql server]-min](https://sqldba.ir/wp-content/uploads/2024/01/tempdb-در-sql-server-min-120x86.jpg)






دیدگاه ها 1