حذف ردیف های تکراری در جدول های SQL Server
فرض کنیم در هنگام اجرای یک کوئری Insert به اشتباه دو بار دستورات را اجرا کرده و مقدار زیادی دیتای تکراری ایجاد کرده ایم و یا به هر علت دیگه ای دیتای تکراری زیادی در جداول خود داریم . خب قطعا Duplicate بودن یک سری دیتا اگر در بیزینس برنامه ما تاثیری نداشته باشه در Performance به نسبت حجم تاثیر خودش رو میذاره مخصوصا اگر بر روی جدول ما تعداد کوئری زیادی اجرا می شود .
در چند روش به بررسی این موضوع میپردازیم .
در دیتابیس AdvantureWorks2019 در جدول Person اسکریپت زیر را اجرا میکنیم .
SELECT BusinessEntityID,FirstName,LastName
FROM [AdventureWorks2019].[Person].[Person]
WHERE FirstName = 'ken' AND LastName = 'Myer'
نتیجه خروجی این اسکریپت به شکل زیر می باشد :
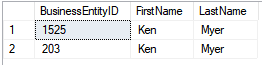
در عکس بالا مشاهده میکنیم که از یک نام و نام خانوادگی 2 بار در جدول موجود است و اینجا فقط یک مثال بوده و ممکنن است برای شما این مقدار خیلی بیشتر تکرار شده باشد .
یکی از راه هایی که می توان مطمعن شد این مقادیر چقدر می باشد استفاده از عبارت Distinct است .
این دستور با تجمیع مقادیر مشابه در خروجی فقط یک مقدار از مقادیر تکراری را نمایش می دهد . مثلا در مثال بالا فقط یک ردیف را نمایش می دهد .
با اجرای اسکریپت های زیر می توان تعداد دیتای تکراری را مشاهده کرد و به صورت ظاهری با Select عادی خود مقایسه کرد :
SELECT DISTINCT (FirstName),LastName
FROM [AdventureWorks2019].[Person].[Person]
WHERE FirstName = 'ken' AND LastName = 'Myer'
خب ، راه حلی که می توان این مشکل را حل کرد این است که همه ی ردیف های تکراری حذف و فقط یک ردیف از نوع خود باقی بماند .
در حالتی که در بالا توضیح دادیم با اسکریپت زیر میتوان را استفاده از دستور ROW_NUMBER ردیف های تکراری بر اساس Name را حذف کنیم :
--SQLDBA.IR
WITH DuplicateRows as
(
SELECT*, ROW_NUMBER() over (PARTITION BY FirstName ORDER BY FirstName) as RowNumber
FROM Person.Person
WHERE FirstName = 'ken' AND LastName = 'Myer'
)
DELETE from DuplicateRows where RowNumber > 1
در مثال بالا با توجه به دیتای خود اسکریپت را می توان تغییر داد و تعداد واقعی دیتای دوبله را مشاهده کرد .
برای دانلود دیتابیس Adventurework 2019 از وبسایت مایکروسافت به لینک زیر مراجعه کنید .










دیدگاه ها 1