توضیحات کامل درمورد High Availability در sql server
High Availability (HA) یک ویژگی مهم در SQL Server است که هدف اصلی آن حفظ دسترسی به دادهها و خدمات پایگاه داده بدون اختلال و توقف است. در زیر، توضیحات کامل در مورد High Availability در SQL Server را مشاهده میکنید:
- تعریف High Availability (HA):
High Availability به معنای دسترسی به دادهها و خدمات بدون اختلال و توقف ناگهانی است. در محیط پایگاه داده SQL Server، High Availability برای حفظ دسترسی به دادهها و ادامه خدمات در صورت بروز مشکلات، از جمله خرابی سختافزاری یا نرمافزاری، طراحی میشود.
- اجزای High Availability در SQL Server:
High Availability در SQL Server اغلب با استفاده از اجزای زیر پیادهسازی میشود:
الف. Failover Clustering:
– در این رویکرد، چندین سرور (نود) در یک گروه قرار میگیرند و از یک منبع مشترک دسترسی به دادهها را دارند.
– در صورت خرابی یک نود، دیگر نود به صورت خودکار به عنوان منبع اصلی تغییر میکند (Failover).
– این روش اغلب باعث حفظ دسترسی بدون اختلال به دادهها میشود.
ب. Database Mirroring:
– این رویکرد در SQL Server 2012 به عنوان منسوخ شده اعلام شده است. در SQL Server 2012 به بعد، به جای Database Mirroring، AlwaysOn Availability Groups را استفاده کنید.
ج. AlwaysOn Availability Groups:
– یک راهکار High Availability و Disaster Recovery متقدم که از SQL Server 2012 به بعد در دسترس است.
– این رویکرد به شما امکان ایجاد گروههای از دیتابیسها (Availability Groups) با دسترسی به یک یا چند کپی از دادهها را میدهد.
– توانایی Failover به صورت دستی یا خودکار با توجه به نیازها.
د. Log Shipping:
– یک روش ساده و کم هزینه برای High Availability که با انتقال کپیهای لاگ تراکنشها از یک سرور به سرور دیگر، امکان بازگردانی دیتابیس در صورت خرابی را فراهم میکند.
– معمولاً برای محیطهای کوچکتر یا به عنوان یک گزینه DR (Disaster Recovery) مورد استفاده قرار میگیرد.
ه. Replication:
– این روش به شما امکان ایجاد و نگهداری چندین کپی از دادهها در مکانهای مختلف را میدهد.
– دادهها به صورت آسنکرون از یک مکان به مکان دیگر انتقال مییابند.
– Replication به عنوان یک روش موازی بهتر استفاده میشود و معمولاً برای محیطهای پرترافیک یا برنامههای خاص مورد
استفاده قرار میگیرد.
- فواید High Availability در SQL Server:
– حفظ دسترسی:
– امکان ادامه عملیات و خدمات بدون اختلال در صورت بروز مشکلات.
– کاهش توقفها:
– کاهش زمان توقفها به حداقل.
– افزایش قابلیت اطمینان:
– افزایش قابلیت اطمینان سیستم و دادهها.
– پشتیبانی از طرحهای Disaster Recovery:
– امکان استفاده از این سیستمها به عنوان بخشی از طرحهای Disaster Recovery.
- چالشها و نکات مهم:
– هزینه:
– برخی از راهکارهای High Availability هزینهبر هستند.
– پیکربندی و مدیریت:
– نیاز به تجربه و دانش برای پیکربندی و مدیریت درست High Availability.
– اهمیت توسعه هماهنگ:
– برنامههای کاربردی باید برای کار با راهکارهای High Availability هماهنگ شوند.
High Availability در SQL Server یک ضرورت برای محیطهای تجاری حساس به زمان است و انتخاب یک روش مناسب بر اساس نیازها و شرایط محیط، اهمیت دارد.
توضیحات کامل در مورد راه اندازی Failover Clustering
راهاندازی Failover Clustering یک روش برای ایجاد High Availability در SQL Server است که از اینجا میتوانید توضیحات کامل در مورد این روش را بخوانید:
- تعریف Failover Clustering:
Failover Clustering یک راهکار High Availability است که بر روی یک گروه از سرورها (نودها) تکیه دارد. در صورتی که یکی از سرورها خراب شود یا دچار مشکل شود، کل خدمات به صورت خودکار به سرور دیگر منتقل میشود. این عملیات که به Failover معروف است، تا حد امکان از دید کاربران نهایی شفاف است.
- اجزای Failover Clustering:
Failover Clustering شامل اجزای زیر است:
الف. نودها (Nodes):
– نودها سرورهای فیزیک یا مجازی هستند که در یک گروه قرار دارند.
– هر نود مجهز به سختافزار و نرمافزار مناسب برای اجرای SQL Server و سیستم عامل است.
ب. منبع ذخیرهسازی مشترک (Shared Storage):
– یک ذخیرهسازی مشترک بین نودها که دادههای SQL Server را در بر دارد.
– معمولاً از تکنولوژیهای مانند Storage Area Network (SAN) استفاده میشود.
ج. Failover Cluster Instance (FCI):
– یک Failover Cluster Instance شامل یک گروه از نودها و یک منبع ذخیرهسازی مشترک است.
– FCI یک نمونه از SQL Server است که بر روی نودها اجرا میشود و از نظر کاربران به عنوان یک سرویس یکپارچه دیده میشود.
- فرآیند راهاندازی Failover Clustering:
الف. آمادهسازی سختافزار و نرمافزار:
– مطمئن شوید که سختافزار نودها مناسب باشد و درایورها و تنظیمات مورد نیاز بر روی هر نود نصب شده باشد.
ب. راهاندازی نودها و نصب SQL Server:
– نودها راهاندازی شده و سیستم عامل و SQL Server بر روی هر نود نصب شود.
ج. تنظیمات Failover Clustering در Windows Server:
– نودها به عنوان اعضای یک گروه Cluster تنظیم شوند.
– تنظیمات مشترک مانند Shared Storage و نحوه ارتباط بین نودها پیکربندی شود.
د. ایجاد Failover Cluster Instance (FCI):
– FCI ایجاد شده و با استفاده از منبع ذخیرهسازی مشترک به نودها متصل شود.
ه. تست Failover:
– عملکرد Failover را تست کنید تا اطمینان حاصل شود که در صورت نیاز، سرویس به صورت صحیح به نود دیگر منتقل میشود.
- فواید Failover Clustering:
– پوشش High Availability:
– حفظ دسترسی به دادهها در صورت خرابی یک یا چند نود.
– پوشش Disaster Recovery:
– توانایی بازیابی سریع در صورت حوادث ناگهانی.
– توسعه پذیری:
– افزودن نودهای جدید به گروه Cluster برای افزایش توانایی پردازش و ذخیرهسازی.
- چالشها و نکات مهم:
– هزینه:
– هزینهبر بودن این راهکار از لحاظ تجهیزات و مدیریت.
– پیچیدگی پیکربندی:
– نیاز به دانش و تجربه برای پیکربندی صحیح.
– توسعه هماهنگ:
– برنامههای کاربردی باید برای کار با Failover Clustering هماهنگ شوند.
راهاندازی Failover Clustering نیازمند مدیریت دقیق و برنامهریزی مناسب است، اما در عوض ارائه حل High Availability بسیار قوی و ایمن است
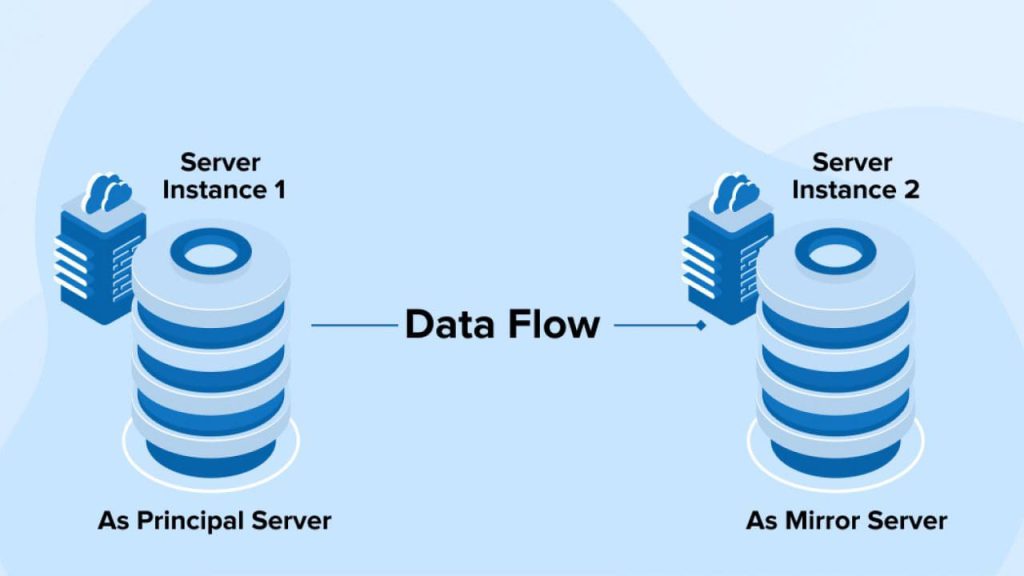
توضیحات کامل در مورد راه اندازی Database Mirroring
Database Mirroring یک راهکار High Availability در SQL Server است که به شما امکان فراهم آوردن یک نسخه تطابقی از دیتابیس در سرور مجاور با امکان Failover فوری را میدهد. در زیر، توضیحات کامل در مورد راه اندازی Database Mirroring آورده شده است:
- تعریف Database Mirroring:
Database Mirroring یک تکنیک High Availability در SQL Server است که به صورت نزدیک به زمان واقعی دادههای یک دیتابیس را بین دو سرور متصل به هم (Principal و Mirror) همگام نگه میدارد. در صورتی که سرور اصلی (Principal) دچار مشکل شود، دیتابیس به صورت خودکار به سرور میرور (Mirror) منتقل میشود.
- اجزای Database Mirroring:
Database Mirroring شامل اجزای زیر است:
الف. Principal Server:
– سرور اصلی که بر روی آن دیتابیس اصلی در دسترس است.
ب. Mirror Server:
– سرور میرور که دیتابیس اصلی به صورت همگام بر روی آن تکثیر میشود.
ج. Witness Server (Optional):
– یک سرور شاهد که در برخی حالات میتواند نقش تصمیمگیرنده در فیلاور (Failover) داشته باشد.
- فرآیند راهاندازی Database Mirroring:
الف. آمادهسازی سرورها:
– سختافزار و نرمافزار سرورها باید برای استفاده از Database Mirroring آمادهسازی شوند.
ب. پیکربندی Principal Server:
– مشخص کردن دیتابیسهایی که میخواهید میرور شوند.
– ایجاد حساب کاربری با دسترسیهای لازم.
ج. پیکربندی Mirror Server:
– مشخص کردن سرور میرور و ایجاد حساب کاربری متناظر با سرور اصلی.
د. پیکربندی Witness Server (Optional):
– در صورت نیاز به افزایش اطمینان در فیلاور، ایجاد حساب کاربری و نصب شاهد.
ه. تنظیم دادههای همگام:
– انتخاب حالت مورد نظر برای همگامسازی دادهها (Synchronous یا Asynchronous).
و. شروع Database Mirroring:
– شروع فرآیند Database Mirroring و انتظار برای ایجاد اتصال همگام.
- فواید Database Mirroring:
– High Availability:
– امکان ادامه خدمات در صورت خرابی سرور اصلی.
– تطابق نزدیک به زمان واقعی:
– انتقال دادهها به سرور میرور در نزدیکترین حالت به زمان واقعی.
– تست Failover:
– امکان تست فرآیند Failover بدون تاثیر بر خدمات فعلی.
- چالشها و نکات مهم:
– مصرف منابع:
– افزایش مصرف منابع سرور به دلیل همگامسازی دادهها.
– تأخیر در همگامسازی:
– ممکن است در همگامسازی دادهها تأخیرهایی رخ دهد.
– پیچیدگی پیکربندی:
– نیاز به دانش فنی برای پیکربندی صحیح.
Database Mirroring یک راهکار ایمن و کارآمد برای High Availability در SQL Server است، اما نیازمند مدیریت دقیق و برنامهریزی مناسب است.
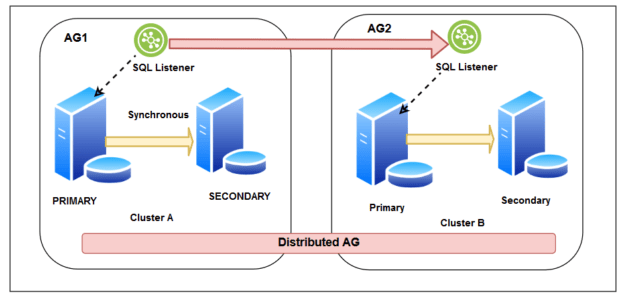
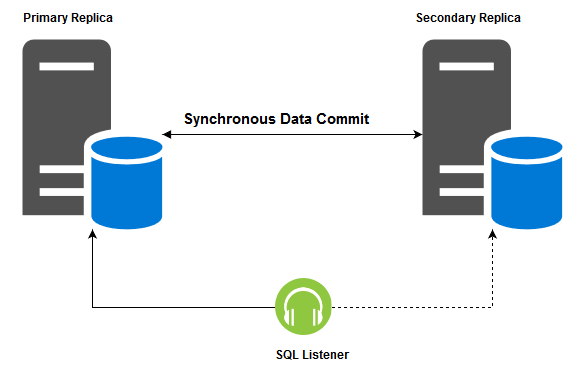
توضیحات کامل درمورد AlwaysOn Availability Groups
AlwaysOn Availability Groups یک راهکار High Availability و Disaster Recovery (HA/DR) در Microsoft SQL Server است که از نسخه 2012 به بعد ارائه شده است. این تکنولوژی به شما امکان ایجاد گروههایی از دیتابیسها (Availability Groups) با دسترسی به یک یا چند کپی از دادهها را میدهد. در زیر، توضیحات کامل در مورد AlwaysOn Availability Groups آورده شده است:
- تعریف AlwaysOn Availability Groups:
AlwaysOn Availability Groups یک تکنولوژی HA/DR در SQL Server است که به شما امکان ایجاد گروههایی از دیتابیسها بر روی سرورهای متصل به هم (نودها) را میدهد. این گروهها دارای یک یا چند دیتابیس اصلی (Primary) و یک یا چند دیتابیس میرور (Secondary) هستند که به صورت همگام یا ناهمگام با دادههای دیتابیس اصلی مطابقت دارند.
- اجزای AlwaysOn Availability Groups:
AlwaysOn Availability Groups شامل اجزای زیر است:
الف. Availability Group:
– یک گروه از دیتابیسهای مرتبط که به صورت همگام یا ناهمگام بین نودها مطابقت دارند.
ب. Primary Replica:
– نود اصلی که دیتابیسها در آن قرار دارند.
– تمامی نوشتنها و خواندنها در این نود انجام میشود.
ج. Secondary Replica:
– نودهای میرور که یک یا چند کپی از دیتابیسها را دریافت کردهاند.
– خواندنها میتوانند از این نودها انجام شوند و در برخی حالات نوشتنها نیز ممکن است.
د. Listener:
– یک DNS نام که به دسترسی به گروه Availability از طریق نودهای مختلف کمک میکند.
ه. Availability Replicas:
– هر نود (Primary یا Secondary) یک Replica نامیده میشود.
- فرآیند راهاندازی AlwaysOn Availability Groups:
الف. آمادهسازی سرورها:
– سختافزار و نرمافزار سرورها باید برای استفاده از AlwaysOn Availability Groups آمادهسازی شوند.
ب. پیکربندی دسترسی:
– تأیید دسترسیها و نقشها بین نودها.
ج. ایجاد گروه Availability:
– انتخاب دیتابیسهای مرتبط و ایجاد گروه Availability.
د. اضافه کردن Replicaها:
– افزودن نودهای Primary و Secondary به گروه Availability.
ه. پیکربندی Listener:
– تنظیم Listener برای دسترسی به گروه Availability.
و. پیکربندی نحوه همگامسازی:
– تعیین نحوه همگامسازی دادهها بین نودها (همگام یا ناهمگام).
ز. آغاز AlwaysOn Availability Groups:
– شروع فرآیند AlwaysOn Availability Groups و انتظار برای ایجاد اتصالات میان نودها.
- فواید AlwaysOn Availability Groups:
– High Availability:
– حفظ دسترسی به دیتابیسها در صورت خرابی سرور اصلی.
– تطابق نزدیک به زمان واقعی:
– امکان ایجاد دیتابیسهای میرور به نزدیکی زمان واقعی.
– خواندن از Replicaها:
– امکان خواندن از Replicaها برای توزیع بار خواندن.
– مدیریت Failover:
– امکان مدیریت فرآیند Failover به صورت دستی یا خودکار.
- چالشها و نکات مهم:
– پیچیدگی پیکربندی:
– نیاز به دانش و تجربه برای پیکربندی صحیح.
– نیاز به Enterprise Edition:
– AlwaysOn Availability Groups نیاز به نسخه Enterprise از SQL Server دارد.
AlwaysOn Availability Groups یک راهکار قوی و انعطافپذیر برای High Availability و Disaster Recovery در SQL Server است که برای محیطهای تجاری حساس به زمان مناسب است.

توضیحات کامل در مورد راه اندازی Log Shipping
Log Shipping یک راهکار Disaster Recovery (DR) در SQL Server است که به شما امکان انتقال و بازیابی مداوم دادهها بین یک سرور اصلی و یک یا چند سرور مخزن فراهم میکند. این روش به طور خاص برای محیطهایی که به دنبال یک راه حل ایمن و کم هزینه برای Disaster Recovery هستند، مناسب است. در زیر، توضیحات کامل در مورد راه اندازی Log Shipping آورده شده است:
- تعریف Log Shipping:
Log Shipping یک تکنیک DR است که به شما این امکان را میدهد که تغییرات در دادهها را از یک سرور (سرور اصلی) به یک یا چند سرور دیگر (سرورهای مخزن) منتقل کنید. این انتقال از طریق کپی کردن و انتقال فایلهای Log SQL Server انجام میشود.
- اجزای Log Shipping:
Log Shipping شامل اجزای زیر است:
الف. Primary Database:
– دیتابیس اصلی که تغییرات آن باید به سرورهای مخزن منتقل شود.
ب. Secondary Databases:
– دیتابیسهای مخزن که تغییرات از دیتابیس اصلی در آنها بازیابی میشوند.
ج. Transaction Log Backup:
– فایلهای پشتیبان تراکنشهای لاگ که تغییرات دادهها را در دیتابیس اصلی ذخیره میکند.
د. Copy Job:
– وظیفه کپی کردن فایلهای Log Backup از سرور اصلی به سرورهای مخزن.
ه. Restore Job:
– وظیفه بازیابی تغییرات از فایلهای Log Backup در دیتابیسهای مخزن.
- فرآیند راهاندازی Log Shipping:
الف. آمادهسازی دیتابیسها:
– تنظیم دیتابیسها برای استفاده از Log Shipping.
ب. تنظیم Backup Schedule:
– تنظیم زمانبندی برای ایجاد فایلهای Backup تراکنشهای لاگ.
ج. پیکربندی سرورهای مخزن:
– تعیین سرورهای مخزن و ایجاد دیتابیسهای مخزن.
د. پیکربندی Jobs:
– ایجاد و تنظیم وظایف Copy و Restore برای منتقل کردن و بازیابی تغییرات.
- فواید Log Shipping:
– Disaster Recovery:
– امکان بازیابی سریع در صورت خرابی دیتابیس اصلی.
– کاهش زمان توقف:
– کاهش زمان توقف به حداقل در مقایسه با راهکارهای دیگر DR.
– مناسب برای دیتابیسهای بزرگ:
– عملکرد مناسب برای دیتابیسهای حجیم با حجم تراکنشهای زیاد.
- چالشها و نکات مهم:
– تاخیر در بازیابی:
– ممکن است تاخیرهایی در بازیابی تغییرات به دیتابیسهای مخزن وجود داشته باشد.
– پیچیدگی مدیریت:
– نیاز به مدیریت دقیق برای پیکربندی صحیح و مدیریت Jobs.
Log Shipping یک راهکار قدرتمند و کارآمد برای Disaster Recovery در SQL Server است که برای محیطهایی با نیاز به راه حل ساده و کم هزینه مناسب است.

توضیحات کامل در مورد راه اندازی Replication در sql server
توضیحات کامل در مورد راه اندازی Replication در SQL Server:
- تعریف Replication:
Replication یک تکنیک در SQL Server است که به شما امکان میدهد دادهها را از یک دیتابیس به دیگری منتقل کنید و آنها را همگام نگه دارید. این عملیات شامل انتقال تغییرات ساختار داده، دیتا، یا هر دو میشود.
- انواع Replication:
در SQL Server، سه نوع اصلی از Replication وجود دارد:
الف. Transactional Replication:
– همگامسازی بین دیتابیس اصلی و دیتابیسهای مشترک به صورت تراکنش به تراکنش.
– بهترین عملکرد برای تغییراتی است که به سرعت به دیتابیسهای مشترک منتقل میشوند.
ب. Snapshot Replication:
– تصویری از دادهها ایجاد میشود و به دیتابیسهای مشترک منتقل میشود.
– برای دیتابیسهایی که تغییرات در آنها کمتر اتفاق میافتد مناسب است.
ج. Merge Replication:
– همگامسازی بین دیتابیس اصلی و دیتابیسهای مشترک به صورت دوطرفه (تغییرات هر دو طرف را با هم همگام میکند).
– مناسب برای سناریوهایی که تغییرات در هر دو سمت بوجود میآیند.
- انواع اشیاء Replication:
در Replication، اشیاء مختلفی را میتوان همگام کرد:
الف. Tables:
– جداول دیتابیس که تغییرات در آنها همگام میشوند.
ب. Views:
– نماهای دیتابیس که مشاهدههای مختلفی از دادهها را نشان میدهند.
ج. Stored Procedures:
– پروسیجرهای ذخیرهشده که در دیتابیسهای مشترک ایجاد میشوند.
- مراحل راهاندازی Replication:
الف. تنظیم نودها:
– تنظیم نود اصلی و نودهای مشترک.
ب. انتخاب نوع Replication:
– انتخاب مناسبترین نوع Replication بر اساس نیازها.
ج. پیکربندی Publication:
– ایجاد Publication برای مشخص کردن چه دادههایی باید همگام شوند.
د. پیکربندی Subscription:
– ایجاد Subscription برای مشخص کردن کدام دیتابیسها باید تغییرات را دریافت کنند.
ه. پیکربندی ویژگیهای همگامسازی:
– تنظیم ویژگیهای همگامسازی بر اساس نیازهای تحلیلی.
- مزایا و چالشها:
مزایا:
– همگامی داده:
– امکان همگامی داده بین نودها.
– قابلیت پیشرفته:
– انعطاف پذیری در انتخاب نوع Replication بر اساس نیازها.
چالشها:
– مدیریت پیچیده:
– مدیریت و پیکربندی پیچیده و نیاز به دانش فنی.
– هزینه منابع:
– مصرف منابع بیشتر برای ایجاد و حفظ همگامی.
Replication یک راهکار قدرتمند برای همگامسازی دادهها در SQL Server است، اما نیازمند مدیریت دقیق و برنامهریزی مناسب است.
تنظیمات کلاسترینگ در ویندوز سرور
تنظیمات کلاسترینگ در ویندوز سرور به منظور افزایش دسترسی و اطمینان به سرویسها و برنامهها میباشد. کلاسترینگ به صورت اجمالی به ایجاد یک گروه از دو یا چند سرور به منظور افزایش توانایی اطمینان (High Availability) و بهبود عملکرد سرویسها اشاره دارد. در ویندوز سرور، این ویژگی از طریق سرویس Failover Clustering فراهم میشود. در زیر توضیحاتی در مورد تنظیمات کلاسترینگ در ویندوز سرور آورده شده است:
- نصب سرویس Failover Clustering:
– ابتدا برای استفاده از کلاسترینگ، سرویس Failover Clustering باید در ویندوز سرور نصب شود.
– این کار را میتوانید از طریق “Server Manager” در ویندوز انجام دهید.
- تهیه اطلاعات DNS:
– برای کلاسترینگ، نیاز به یک نام DNS (Domain Name System) است. این نام باید از قبل در DNS سازمان ثبت شده باشد.
- پیکربندی شبکه:
– اطمینان حاصل شود که تمام سرورهای شرکت کننده در کلاستر، به یکدیگر دسترسی دارند.
– شبکهها بهصورت صحیح پیکربندی شده باشند.
- افزودن سرورها به کلاستر:
– از طریق “Failover Cluster Manager”، سرورهای موردنظر را به کلاستر افزوده و تنظیمات احراز هویت (Authentication) را انجام دهید.
- تنظیمات ذخیرهسازی مشترک:
– اگر کلاستر از ذخیرهسازی مشترک استفاده میکند، اطمینان حاصل شود که تنظیمات ذخیرهسازی صحیح انجام شده باشد.
- ایجاد نقطه فیلنور (File Share Witness):
– در صورت نیاز، یک نقطه فیلنور برای افزایش اطمینان کلاستر ایجاد شود.
- تنظیمات سرویسها و برنامهها:
– هر سرویس یا برنامهای که میخواهید در کلاستر اجرا شود، باید بهصورت صحیح پیکربندی شده باشد.
– این ممکن است شامل تنظیمات خاصی برای همگامسازی دادهها، ایجاد نقطه بازیابی (Checkpoint)، و موارد دیگر باشد.
- تست Failover:
– پس از تمام تنظیمات، تست فایلاور (تغییر نقش سرویس از یک سرور به سرور دیگر) را انجام دهید تا اطمینان حاصل شود که کلاستر بهدرستی عمل میکند.
- نظارت و مدیریت:
– از ابزارهای مدیریتی مانند “Failover Cluster Manager” و “PowerShell” برای نظارت و مدیریت کلاستر استفاده کنید.
- تنظیمات متقابل:
– در مواردی که برنامهها و سرویسها نیاز به تنظیمات خاصی دارند، تنظیمات مربوط به محیط کلاستر نیز باید با توجه به نیازهای آنها اعمال شود.
با اجرای مراحل فوق، میتوانید یک کلاسترینگ قوی و پایدار را در ویندوز سرور پیکربندی کنید. حضور کلاستر به معنای افزایش اطمینان و همگامسازی بهبود عملکرد سرویسها و برنامههاست.










دیدگاه ها 2